Automating Helmet Compliance at Ski Resorts
David Ristau, Courtney Smith, Grant Wilson, and Chandler Haukap
Overview
Skiing and snowboarding are extremely popular sports both globally and domestically, with 462 ski resorts operating in the United States alone in 2021 (NSAA 2022). The subsidiaries of Vail Resorts alone reported a net income of 127.9 million dollars in the fiscal year 2021 (Vail Resorts 2022). These figures are expected to grow as COVID-19 lockdown restrictions and visitor limits are lifted.
Increased visitor counts also increase the risk of injuries as trails and lifts get more crowded and trail conditions deteriorate. Proper equipment is paramount in preventing injuries. The US Consumer Product Safety Commission found that around 50% of head injuries could be prevented by the use of a helmet. Although several countries have mandated helmet use for children, and several US states have considered mandatory helmet legislation, the majority of US ski resorts do not currently mandate helmets for children or adults; this may be partially due to difficulties around monitoring helmet usage or enforcing compliance. (Haider, Saleem, Bilaniuk, and Barraco 2014). We believe that an automated system that detects helmets could make compliance easier to enforce. Additionally, the system will give a more accurate view of the rates of helmet usage for skiers and snowboarders.
Leveraging existing deep learning frameworks, our group was able to design a helmet detection system that can be deployed on edge devices for use at ski resorts.
Data
Unfortunately, we could not locate a pre-labeled dataset of ski helmets. However, there are multiple datasets that contain skiing images. By aggregating images of skis, we were able to locate well over 1,000 examples of helmet compliance and non-compliance.
The ski images we used came from the Common Objects in Context (COCO) dataset. COCO was created by a team of researchers both from academia and private companies. The dataset itself contains over 150,000 images. We selected COCO because we could easily filter the dataset down to the 6,887 images labeled “ski”. Not all of these images were helpful. Some were too blurry to tell if the wearer of the skis was wearing a helmet. Others contained no human at all or only an image of their legs.


Fortunately, we were able to repurpose 3,262 images that contained not only the skis but also the head of the human wearing them.


Labeling the images was performed by hand. We used Roboflow’s interface to draw the bounding boxes and filter unusable images (Roboflow). There was some debate on whether we should label compliance, i.e. helmets, noncompliance, i.e. bare heads, Or both. We decided to label both. Our decision was based on the fact that the two labels are mutually exclusive. Receiving a label of noncompliance does not impact the model’s decision to also label the image compliant. In this way, we are able to train two image classifiers at once: one that detects bare heads and one that detects helmets. If this model were deployed at a ski resort the operators would be able to choose the most performant label or some combination of the two labels at their discretion.
In addition, generating results of both positive and negative examples would make iterating on the model much easier in the future.


From the 3,262 images, we annotated 2,374 examples of noncompliance and 1,605 examples of helmet use. On average each image contained 1.2 annotations with some images providing more than 6 unique examples. The number of annotations per image is visualized below:
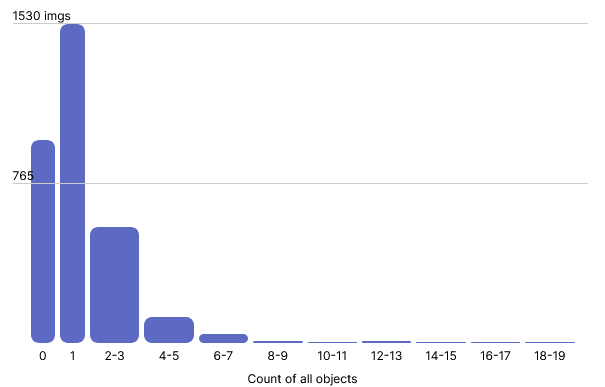
We augmented the data with a horizontal flip that gave us a total of 4,966 images. These images were divided into train/set sets using an 80/20 split for a total of 3,968 training images, 638 validation images, and 360 test images.
Tools and Data Pipeline
To develop this application multiple tools were used in the training pipeline as well as at inference time.
As mentioned previously, the data source for this project was the COCO dataset. We then applied custom labels, ‘helmet’ and ‘no helmet’ to our dataset using Roboflow. Roboflow was a key tool in the model training and iteration phase. Alternative labeling tools that were considered were Open Labeling, Make Sense AI, and AWS sagemaker ground truth. Open labeling and Make Sense AI do not include the ability to manage a dataset or distribute labeling amongst multiple team members. AWS ground truth and Roboflow enable labeling to be distributed amongst multiple team members, however AWS ground truth is more limited in dataset management as well as being relatively costly. Roboflow was selected because it allows for easier modification and versioning of a dataset and is free to use when assembling a public dataset.
During training, each yolov5 model was evaluated using Weights and Biases, otherwise known as wandb (wandb). With wandb each training run is able to be easily compared on multiple metrics. Another particularly useful feature of wandb is the bounding box debugger. This allows images from the validation set to be compared at each step in the training process at multiple confidence thresholds. This enables models to be precisely evaluated to determine the types of mistakes it makes.
At inference time we use several tools to deploy the yolov5 model and save the relevant data to the cloud. Our application pipeline is shown in the diagram below in two possible configurations.
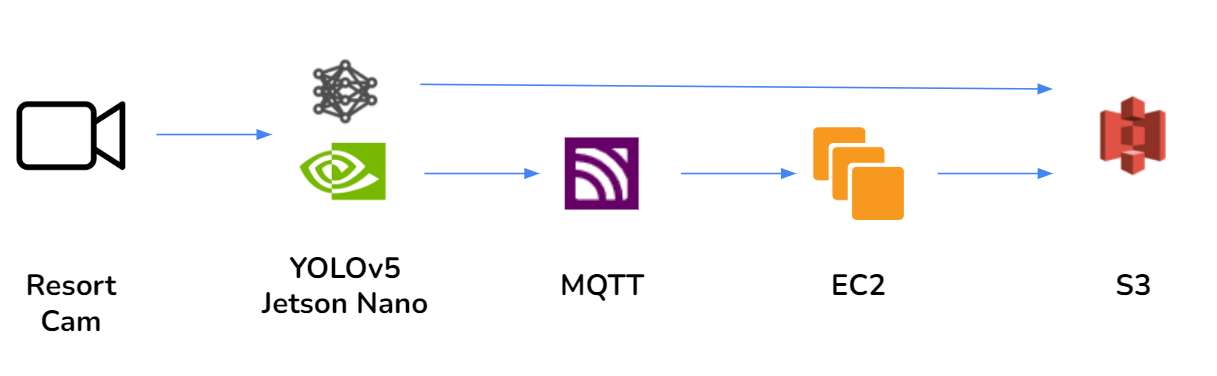
Img sources: [resort cam, yolov5, jetson nano, mqtt, ec2, s3]
The use case we envision for this project would be deployed on an edge device at a ski resort. To simulate this, we used a jetston nano 2gb as our edge device (jetson nano). The yolov5 model runs on this jetson edge device which evaluates a video feed using a USB camera as the input source. As the yolov5 model generates predictions they are saved as a .csv file locally on the Jetson device.
In the first configuration we make the assumption that the cameras that the model is running on have an ethernet connection to the network. In this context, we are able to write our .csv file directly to an s3 bucket using the boto3 python package. This is the simplest configuration, and we believe to be the most realistic since it would be hard to imagine all trail cameras on a large ski resort transmitting over a wifi network.
In the second configuration, we assume that our edge devices are transmitting over an unreliable network connection. In this context we would propose using MQTT as a messaging service to upload the data to an s3 bucket. The jetson device would send the .csv file as a message using MQTT to an EC2 instance in AWS. The messaging quality of service (QoS) that would be used in MQTT is ‘1’ which means the message is sent at least once, giving the highest chance for message delivery. We chose this QoS in this context because we are assuming that network coverage on a ski resort may be intermittent. In the EC2 instance we process the file by saving each csv file into an S3 bucket with a timestamp as the filename.
Our current application operates on the infrastructure described in configuration one. We believe that this is more realistic, and it is much simpler to deploy.
Model Design
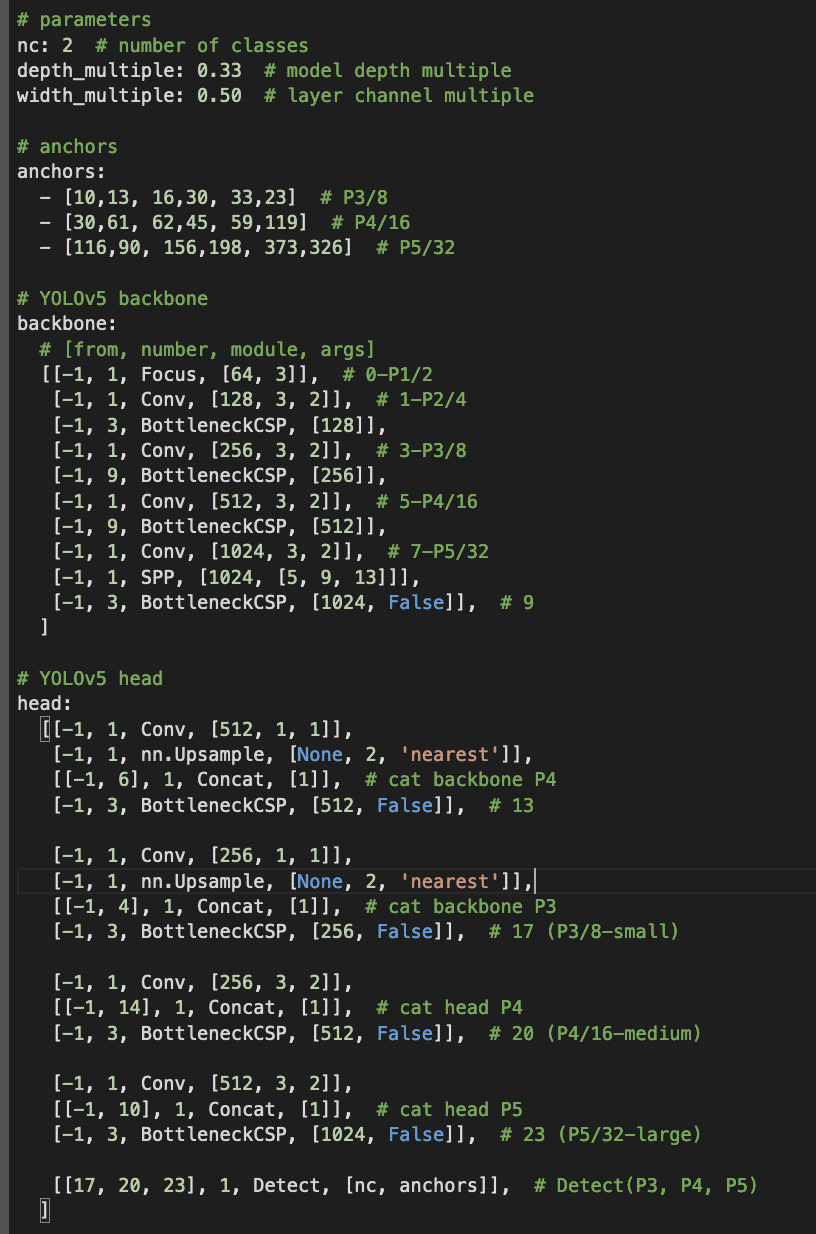
We decided to architect the solution around the YOLOv5 framework given its success in modeling custom classes within image data (YOLOv5). Since we were using RoboFlow to create bounding boxes and preprocess the image dataset, we were easily able to download the processed images via the RoboFlow API, formatted properly for YOLOv5.
As discussed in our previous section, our model is training on images of skiers with helmet and no-helmet classifications. We additionally marked certain irrelevant pictures as null. Below, we see that non-skiing pictures and pictures without subjects in the foreground are excluded. This is to keep the training relevant to the skiing context and reduce error from mislabelling heads that were too far away to determine whether someone was wearing a helmet. This also kept our model from trying to overreach and predict on people that are too far away.
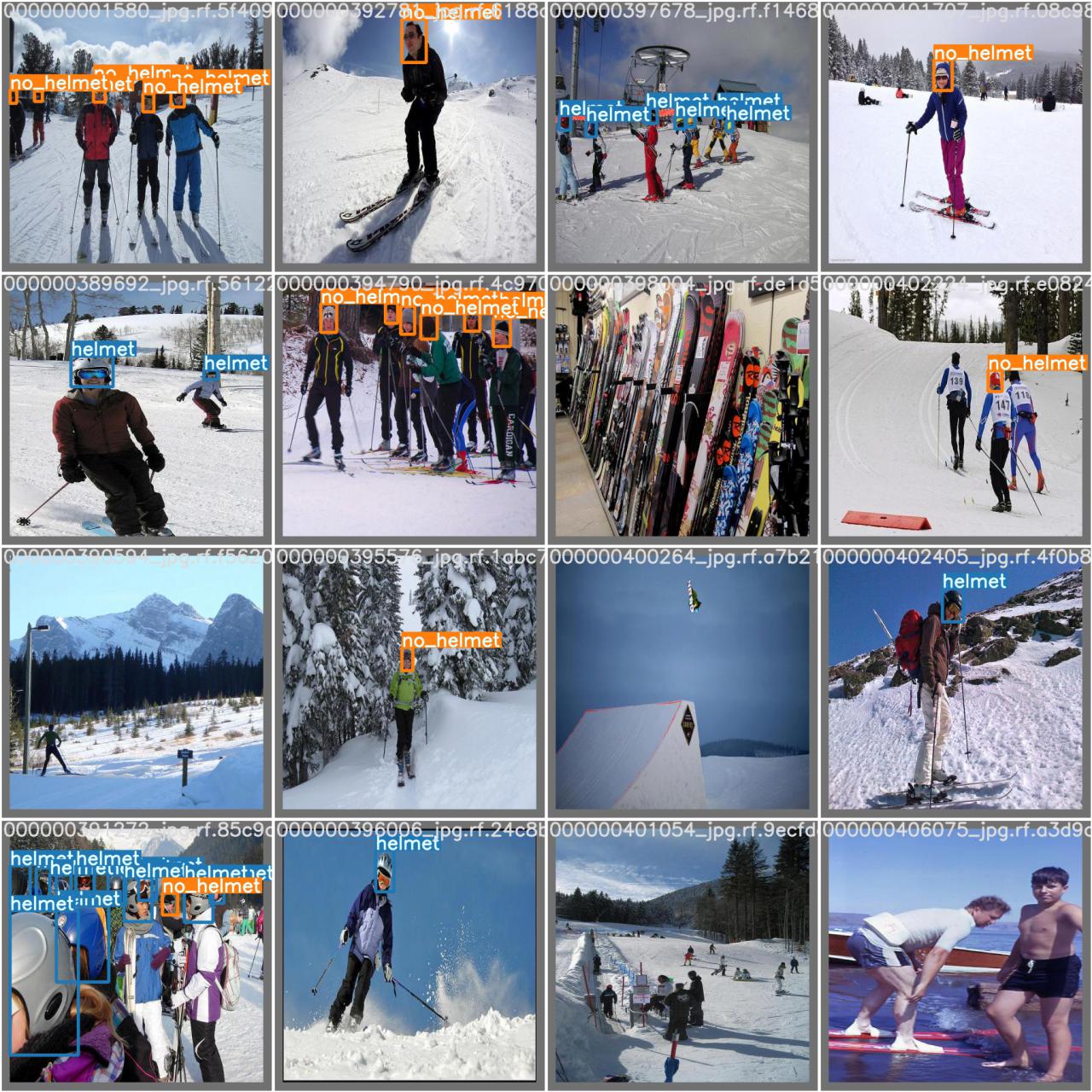
Because our model required strict labeling of helmets vs. hats/beanies/gaiters, we used images that were close enough to a face to make that distinction. This allowed us to use smaller image sizes when training the model. We ended up deciding on 416px images and training for 100 epochs.

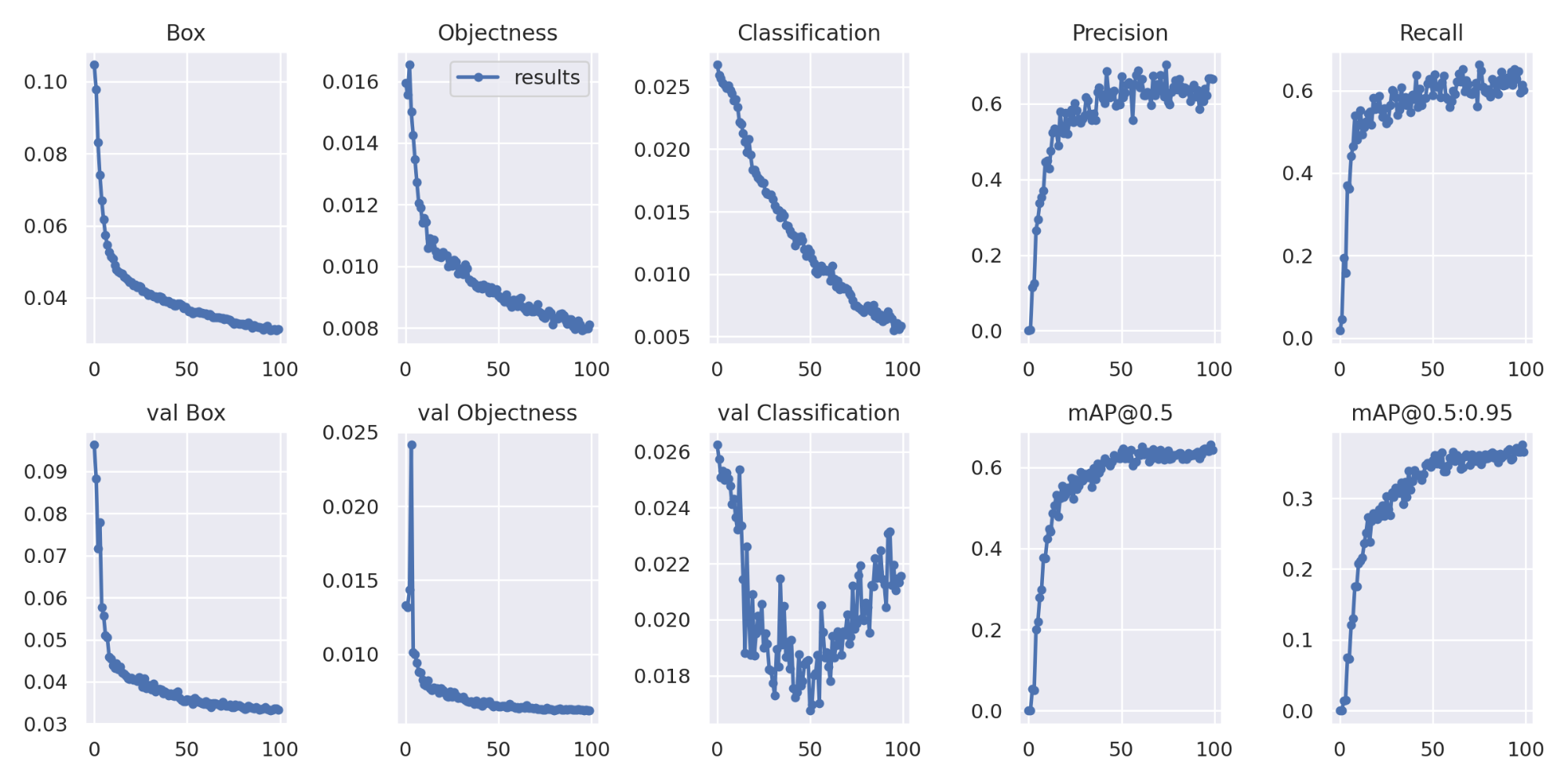
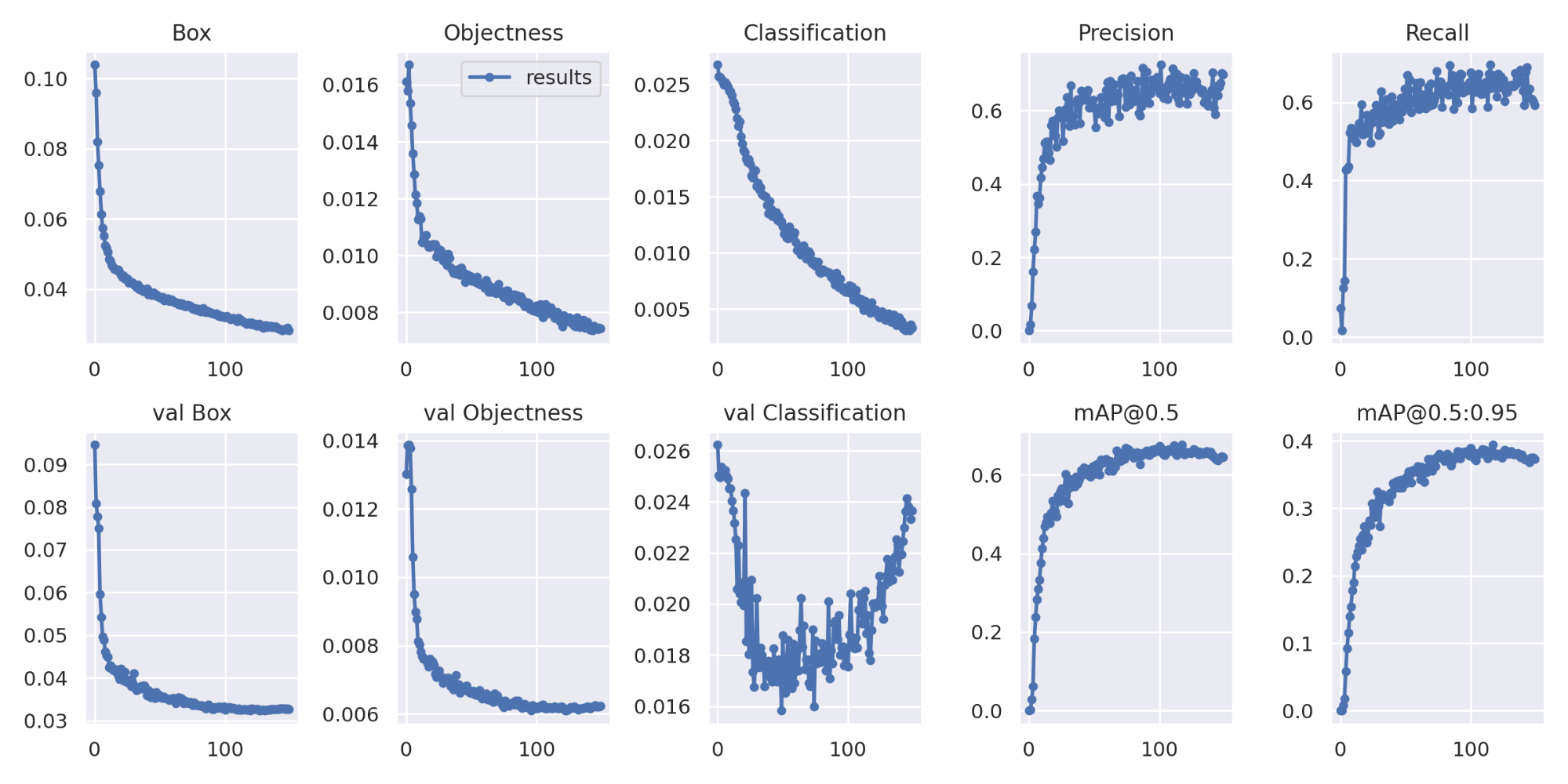
The training process completed in 3.119 hours and produced the results below. Based on our classification error scores, it looks like our model could benefit from more epochs to allow the model to better fit to our training data. We also see that our precision and recall are fairly close together. This means that our accuracy was fairly balanced between false positives and false negatives. For a simple monitoring solution this is probably fine, however if we were to implement this solution to fine skiers that aren’t complying with safety rules, we may want to take greater care to increase the precision so we only fine people who are definitively not wearing helmets.
100 Epochs:
150 Epochs:
{kind=link}
{kind=link}
Challenges
The classifier had difficulty differentiating between helmets and other types of hats and beanies. This difficulty was exacerbated by images that were not head-on, as well as by google positioning. The outline of a helmet or hat was sometimes partially obscured in images where the rider had their goggles pulled up on top of their helmet or hat.
The lower accuracy in images that are not head-on could lead to limitations in the positioning of the edge devices running the helmet detection system. Additionally, the frame is constrained by the Jetson.
Alternative Designs
A design decision that our group had to make early in the process was what to label. Our first thought was to teach the model what a helmet looks like, then train it to look for humans without a corresponding “helmet” label. This method might have been fruitful, but it wouldn’t have told us anything about what it looks like to not wear a helmet.
We also considered labeling only non-compliance. This would have achieved our goal of detecting individuals without helmets, but we worried that this approach might produce less usable data for ski resorts. Looking for only positive examples would make retraining on new examples more difficult.